Table of Contents
What Is Web Scraping?
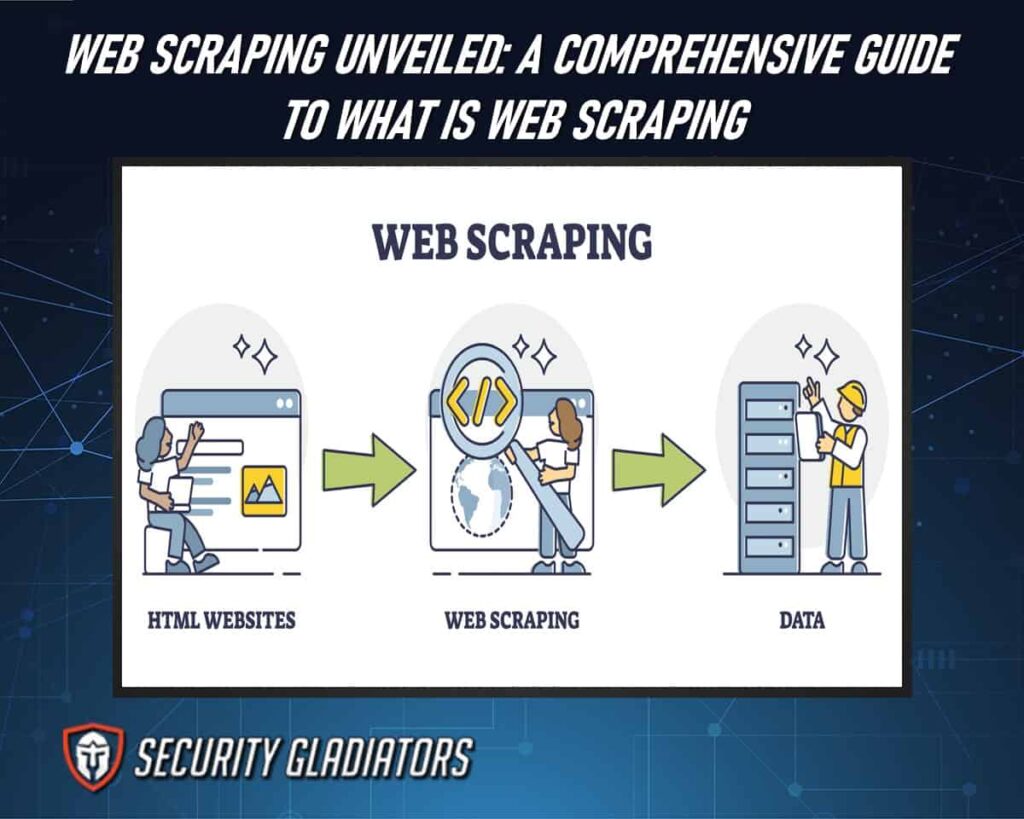
Web scraping is the process of extracting data from a website, enabling users to gather large amounts of information quickly and efficiently. It involves the use of web scraping software that automatically navigates through websites, simulating human browsing behavior and extracting specific data elements. The extracted data can include text, images, links, tables, or any other structured content available on the website. Web scraping has become an essential tool for various industries such as market research, competitive analysis, academic research, and data journalism. By automating the process of gathering data from multiple sources, web scraping allows users to save time and resources while accessing valuable information that would otherwise be tedious or impossible to collect manually.
The Basics of Web Data Extraction
Once you’ve selected the HTML elements you want to extract, you can access their content or attributes programmatically. Common extraction methods include obtaining text content from
elements, attribute values (e.g., href from elements), or structured data from tables or lists.
Here are the basics of web data extraction:
HTTP Requests
Web data extraction starts with making HTTP requests to specific URLs. You can use HTTP libraries like requests in Python to fetch the HTML content of a web page. Understanding the various types of HTTP requests, such as GET and POST, is essential for retrieving the desired data.
HTML Structure
Web pages are written in HTML (HyperText Markup Language). Understanding the structure of HTML is crucial for web data extraction. HTML consists of elements like <html>, <head>, <body>, <div>, <p>, and more, organized in a hierarchical structure.

HTML Parsing
To extract data, you need to parse the HTML content. HTML parsing libraries like BeautifulSoup (Python) or Cheerio (Node.js) create a structured representation of the HTML called the Document Object Model (DOM). The DOM allows you to navigate and manipulate the web page’s elements and content.
Selectors (CSS or XPath)
Selectors are used to target specific elements within the DOM. Two common types of selectors are:
CSS Selectors
These select elements by tag names, classes, IDs, and other attributes. For example, #id selects elements by their ID, and .class selects elements by class.
XPath
XPath expressions are used to navigate and select elements based on their position in the DOM tree. XPath is particularly useful for complex or nested structures.
Data Extraction
What Is the Difference Between Scraping and Crawling
Scraping refers to the process of extracting specific information from websites using automated tools or scripts known as web scraping code. It involves accessing a particular webpage, parsing its HTML structure, and extracting relevant data elements based on predefined patterns or rules. On the other hand, crawling refers to the systematic exploration of multiple web pages by a web crawler or spider. This technique involves traversing through links on websites to discover and retrieve content from various pages. While both scraping and crawling involve fetching data from the web, they differ in their focus and approach. Scraping targets specific information on individual pages, whereas crawling aims to systematically explore and collect information across multiple pages.
The Web Scraping Process
When you want to scrape data from a website, below is the process to follow:
Target Website Identification
Identify the website or web pages from which you want to extract data. Ensure that the chosen source is reliable and contains the information you need.
HTTP Requests
Send HTTP requests to the target website. This involves accessing the web pages using URLs, which might include query parameters to specify what data you want to access.
Retrieve HTML Content
Retrieve the HTML content of the web pages. The HTML contains the structured data that you will parse to extract the information you’re interested in. You can use libraries like requests to perform this step.
HTML Parsing
Parse the HTML content using an HTML parsing library like BeautifulSoup or a framework like Scrapy. This parsing process creates a structured representation of the HTML known as the Document Object Model (DOM), which allows you to navigate and manipulate the content.
Selector Usage
Use CSS selectors or XPath expressions to select specific HTML elements on the web page. These selectors help you pinpoint the data you want to extract. For example, you can select elements by their tag names, attributes, IDs, or classes.
Data Extraction
Extract the relevant data from the selected HTML elements. Depending on your project, this may involve extracting text content, attribute values (e.g., links or image URLs), structured data from tables, or any other information that suits your needs.
Data Cleaning and Transformation
Preprocess the extracted data to ensure its quality and consistency. This includes handling missing or incorrect data, performing data type conversions, and structuring the data according to your requirements.
Iterate Through Pages
If the data spans multiple pages or is paginated, implement logic to iterate through different pages. You may need to modify URLs, follow pagination links, or interact with web page controls to access additional data.
Handle Dynamic Content
Some websites load content dynamically using JavaScript. To scrape these sites, you may need to use headless browser automation tools like Selenium to interact with web pages and retrieve dynamic data.
Store and Use Data
Store the extracted data in a structured format, such as CSV, JSON, a database, or any other suitable storage method. You can then use this data for analysis, reporting, or integration into various applications.
What Is a Web Scraping Tool?
Web scraping tools are instrumental in automating the extraction of data from websites, allowing users to efficiently and objectively gather valuable information for analysis and various applications. A web data extraction tool simplifies the process of scraping data by providing a user-friendly interface that enables users to specify the websites they want to extract data from and define the specific data elements they need. Some web scraping tools offer advanced features such as scheduling automated extractions, handling cookies and JavaScript rendering, and extracting data from dynamic websites. Additionally, these tools support various programming languages like Python, R, Java, or Ruby, allowing users with different coding backgrounds to utilize their preferred language for web scraping tasks. With the help of web scraping tools, researchers can easily collect large amounts of data for academic studies or market research purposes without having to manually visit each website or rely on outdated datasets. Examples of web scraping tools include BeautifulSoup, BeautifulSoup, Selenium, Octoparse, and WebHarvy.
What Are the Alternatives to Data Scraping Software
While data scraping tools are effective for extracting information from websites, there are alternatives and complementary approaches for obtaining data, depending on your specific needs and the nature of the data source.
Here are some alternatives to data scraping tools:
APIs (Application Programming Interfaces)
Many websites and online services provide APIs that allow developers to access and retrieve data in a structured and legal manner. Using APIs is often the preferred method for obtaining data from web services when available.
Web Data Providers
In some cases, you can obtain the data you need from third-party web data providers. These providers offer curated datasets and APIs for various industries and use cases.
RSS Feeds
Websites that publish content like blogs or news often provide RSS feeds that can be subscribed to and used to access their content in a standardized format.
Web Scraping Services
Rather than building and maintaining your own scraping tools, you can use web scraping services and APIs offered by third-party providers. These services often handle the technical details and data processing for you.
Manual Data Entry
For small-scale data extraction tasks, manually copying and pasting data may be a viable option, especially if automation is not necessary.
Uses of Web Scraping
Web scraping has a wide range of applications, including:
Price Intelligence
Price intelligence is a powerful tool that enables businesses to gain a visual representation of pricing trends and fluctuations in the market, providing them with actionable insights for strategic decision-making. With the help of web scraping, businesses can extract data from various e-commerce websites and analyze it to understand how prices are changing over time. By scraping data from multiple sources, such as competitor websites or online marketplaces, businesses can compare their own prices with those of their competitors and identify opportunities to adjust their pricing strategies accordingly. Web scraping allows businesses to gather real-time data on product prices, discounts, promotions, and availability, helping them stay competitive in the market. This valuable information can guide businesses in making informed decisions about pricing strategies, inventory management, product positioning, and overall business performance.
Market Research
Web scraping allows businesses to gather data from various online services and websites to extract specific data points that are relevant to their research objectives. By utilizing web scraping, market research companies can collect data on customer preferences, purchasing patterns, and demographic information in a more efficient and cost-effective manner. This enables businesses to make informed decisions based on accurate and up-to-date information, ultimately giving them a competitive edge in the market.

Alternative Data for Finance
Web scraping is employed in finance as an alternative data source to gather real-time information from various online platforms, enabling analysts and traders to track market sentiment, predict market movements, and make informed investment decisions. By extracting data from sources like social media, news websites, and e-commerce platforms, web scraping provides valuable insights that complement traditional financial data and enhance risk assessment and investment strategies.
Real Estate
By utilizing web scraping bots, investors can gather product and pricing information from various target websites related to real estate. These bots can navigate through multiple pages on these websites to collect comprehensive data that can inform investment decisions. This process allows investors to analyze market trends, compare property prices, and identify potential investment opportunities in the real estate sector. Web scraping in the realm of real estate enables investors to access a wealth of information without relying solely on traditional sources such as brokers or listing platforms.
News & Content Monitoring
With the help of web scraping, businesses can extract news articles, blog posts, social media updates, and other forms of content from multiple websites simultaneously. This enables them to gain insights into customer preferences, market trends, and competitor strategies. Cloud-based web scrapers are particularly useful in this context as they offer scalability, flexibility, and easy access to data from anywhere. Additionally, browser extensions provide an efficient way to scrape information directly from web pages without the need for complex coding.
Lead Generation
Lead generation is another valuable application of web scraping. By using a web scraper, businesses can extract contact information from various online sources to generate leads for their sales and marketing efforts. This process, known as contact scraping, allows organizations to gather data such as email addresses, phone numbers, and social media profiles of potential customers or clients. With the collected information, companies can create targeted marketing campaigns and efficiently reach out to prospects.
Brand Monitoring
Brand monitoring is a crucial aspect of business strategy as it allows organizations to stay updated on consumer perceptions and sentiments towards their brand, ultimately enabling them to make informed decisions and maintain a positive brand image in the market. By actively monitoring their brand online, companies can gain valuable insights into how their products or services are being perceived by customers. This information can help them identify any potential issues or negative feedback and address them promptly, ensuring that customer satisfaction is maintained.
Additionally, brand monitoring allows businesses to track competitor activities and industry trends, helping them stay ahead of the curve and make strategic decisions accordingly. It also provides an opportunity for organizations to engage with customers directly, addressing their concerns or queries in real-time.
Business Automation
Business automation is a transformative process that revolutionizes operational efficiency and enhances productivity, enabling organizations to streamline repetitive tasks, reduce human error, and allocate resources more effectively. By implementing business automation strategies, companies can automate various aspects of their operations such as data entry, customer support, inventory management, and financial processes. This allows employees to focus on more strategic and value-added activities while reducing the time spent on mundane tasks.
Furthermore, business automation helps in standardizing processes and ensuring consistency across different departments or locations within an organization. It also enables businesses to analyze and interpret large volumes of data efficiently, leading to better decision-making and improved overall performance.
MAP Monitoring
MAP monitoring is a strategic process that allows organizations to track and analyze the online presence and pricing of their products across various channels, enabling them to proactively address issues such as unauthorized sellers, price violations, or counterfeit products. This process involves utilizing web scraping techniques to extract data from comparison websites and other online platforms. By using tools like Google Sheets and browser extensions, organizations can automate the data extraction process and gather essential information about their product listings, including prices, availability, and seller details. This enables businesses to monitor market trends, identify pricing discrepancies, and take necessary actions to maintain brand integrity.
Frequently Asked Questions
Is Web Scraping Legal?
The legality of web scraping depends on various factors, including the website’s terms of service, copyright laws, and data privacy regulations. Always respect the website’s policies, and consider obtaining explicit permission or using public APIs when available. Web scraping crosses the legal boundary when it involves extracting data that is not publicly available.
What Are the Ethical Considerations When Web Scraping?
Ethical considerations include obtaining permission when necessary, not overloading servers with requests, and not scraping sensitive or personal data without consent. Transparency and responsible scraping practices are vital.
What Are Some Real-World Applications of Web Scraping in Finance?
Web scraping in finance is used for tasks like tracking stock market news sentiment, collecting financial data, monitoring competitor pricing, and analyzing economic indicators from various online sources.
What Are the Best Practices for Documenting and Maintaining Web Scraping Projects?
It’s essential to document your code, include comments, and maintain clear records of your scraping process. Regularly check and update your scraping scripts to adapt to changes on the target websites.
Conclusion

Understanding the basics of web scraping and its applications can empower businesses with the ability to extract valuable data from websites efficiently and effectively. With proper implementation and adherence to legal guidelines, web scraping has the potential to revolutionize data extraction processes across industries, allowing businesses to gain valuable insights, make informed decisions, and stay ahead of the competition. By automating the data extraction process, businesses can save time and resources, while also ensuring data accuracy and consistency.
